Caracterización de equipos informáticos mediante clustering en una red empresarial
Repositorio: https://github.com/jartigag/tfm-clustering
En la monitorización de redes informáticas a gran escala, resulta de alto interés conocer el comportamiento de sus equipos finales y detectar aquellos que puedan ser sospechosos. Sin embargo, clasificar a cada equipo según su actividad supone un importante ejercicio de síntesis. Además, es difícil obtener unas categorías útiles, sobre todo en el caso de las anomalías, ya que son desconocidas a priori.
El presente trabajo aborda este reto haciendo uso de técnicas de clustering a partir de logs extraídos de firewalls. Con un muestreo del 5 %, que supone un millón de sesiones al día, se han distinguido 5 clases de comportamientos. Los comportamientos anómalos se han conseguido reunir en un solo cluster con menos de diez casos al día.
Para conocer bien de todos los detalles, mejor leer la memoria en pdf.
Índice general
1. Introducción
La monitorización de la red informática en una gran empresa es un problema complejo por muchos factores. El más inmediato podría ser el alto volumen de conexiones que se producen, superior a varios millones diarios. Pero se suman otras muchas dificultades a la hora de procesar el tráfico de forma que se obtenga información útil para el analista y, en última instancia, para el cliente final: la gran variabilidad de comportamientos, la complejidad de sintetizar lo importante sin perder exactitud, el compromiso entre rapidez en la respuesta y certeza en su fiabilidad, el desconocimiento a priori de cómo se caracteriza un comportamiento anómalo, etc.
Interesa buscar una solución a estos obstáculos porque las empresas quieren garantizar que los recursos de sus redes se gestionan de la manera más óptima posible. Además, es especialmente importante la seguridad de la red corporativa, esto es, protegerla de acciones no autorizadas u otras amenazas que puedan comprometer su disponibilidad o la integridad de los equipos que la componen.
Equipos de seguridad como puedan ser los firewalls contribuyen de manera decisiva a esta protección, pero su funcionamiento basado en firmas no cubre todos los casos ante una intrusión. Sin embargo, sí generan una enorme cantidad de datos que, si se tratan adecuadamente, sirven para ampliar el alcance de las técnicas empleadas en materia de seguridad.
Por ello, un sistema que modele el comportamiento normal de una red y detecte anomalías usando métodos estadísticos y de inteligencia artificial permitirá conocer mejor el contexto de dicha red e identificar comportamientos sospechosos que no se considerarían de otro modo.
Las cuestiones planteadas para guiar esta investigación han sido:
-
Si podemos clasificar las direcciones IP de una gran red empresarial en categorías relevantes según su comportamiento de red.
-
Cuáles serían esas categorías.
-
Si sereremos capaces de identificar comportamientos sospechosos en base a esta clasificación.
A través de estas cuestiones se inicia el estudio del problema, para cuya solución se propone obtener un modelo clasificador que distinga patrones de comportamiento normales y desviaciones respecto de la actividad normal. Este clasificador se realizará mediante una técnica de aprendizaje automático no supervisado como es el clustering (técnica que lleva a cabo una agrupación en categorías de manera natural, buscando características en común sin haber definido las clases previamente). El objetivo principal es localizar en la red interna orígenes de tráfico catalogable como extraño, lo que puede indicar un equipo infectado o mal configurado. La determinación de qué se sale de lo habitual dependerá de las particularidades de la red, algo difícil de concretar a priori y más aún de generalizar, razón por la cual el clustering (como etapa final tras un análisis y preprocesado de los datos adaptado al caso) se ha considerado una técnica idónea en esta tarea.
2. Objetivos y metodología
- Procesado (en producción, diario):
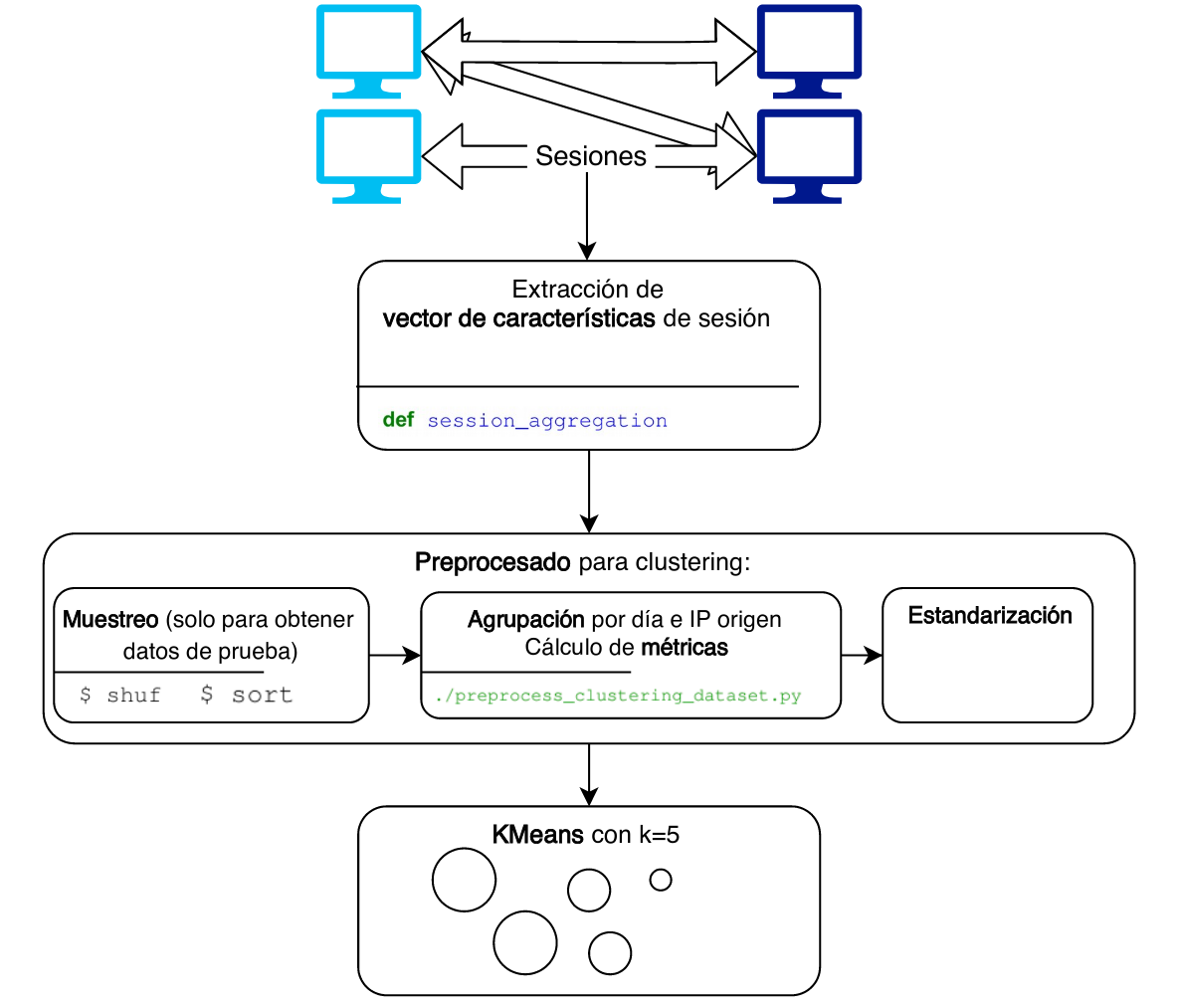
- Dashboard (para monitorizar los resultados desde Grafana):
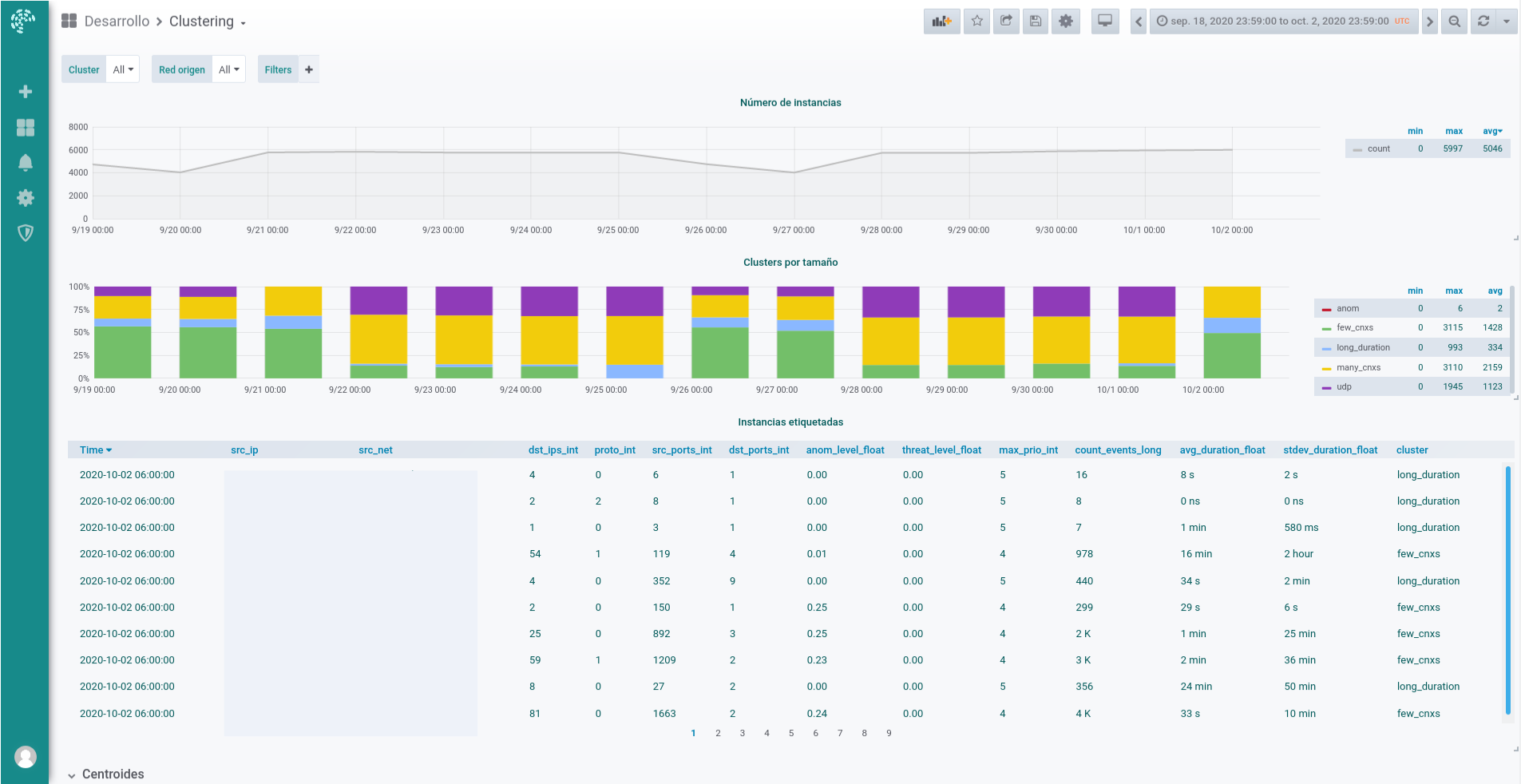
3. Estado del arte
Referencias interesantes:
3.1. Aprendizaje automático en la clasificación de tráfico
"Why Should Machines Learn?" (S. Herbert, 1983)
"Experiences of Internet traffic monitoring with tstat" (A. Finamore et al., 2011)
3.2. Detección de anomalías sobre actividad de red
3.3. Clustering
"Intrusion Detection with Unlabeled Data Using Clustering" (L. Portnoy, 200)
"A clustering-based method for unsupervised intrusion detections" (S. Jian et al., 2006)
"Flow Clustering Using Machine Learning Techniques" (A. McGregor et al., 2004)
"Traffic Classification on the Fly" (L. Bernaille et al., 2006) y conti-nuaciones
"Unsupervised Anomaly Detection in Network Intrusion Detection Using Clusters" (K. Leung y C. Leckie, 2005)
"Network Anomaly Detection: Methods, Systems and Tools" (M.H. Bhuyan, 2014)
"Unsupervised clustering approach for network anomaly detection" (I. Syarif et al., 2012)
"Distance-Based Outlier Detection: Consolidation and Renewed Bearing" (G. H. Orair et al., 2010)
4. Desarrollo
5. Resultados
En septiembre/octubre se llevó el prototipo al escenario real. Se adaptaron los scripts y se obtuvieron las mismas 5 categorías:
1. En los equipos que corresponden a la categoría "comportamiento normal con muchas conexiones", el número de direcciones IPs destino únicas a las que se conectan está en el orden de varios cientos y casi siempre 2 puertos destino (los más frecuentes, 80 y 443) o 3.
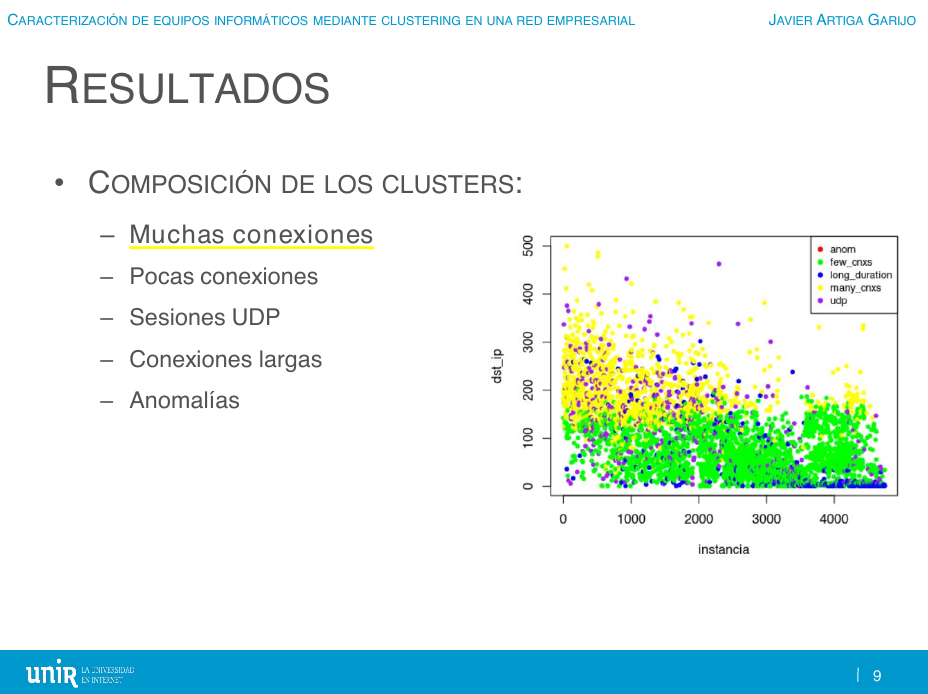
⠀
2. Los equipos de categoría "comportamiento normal, pocas conexiones" se conectan a decenas de IPs destino, usando menos de 100 puertos origen y hacia 1-2 puertos destino.
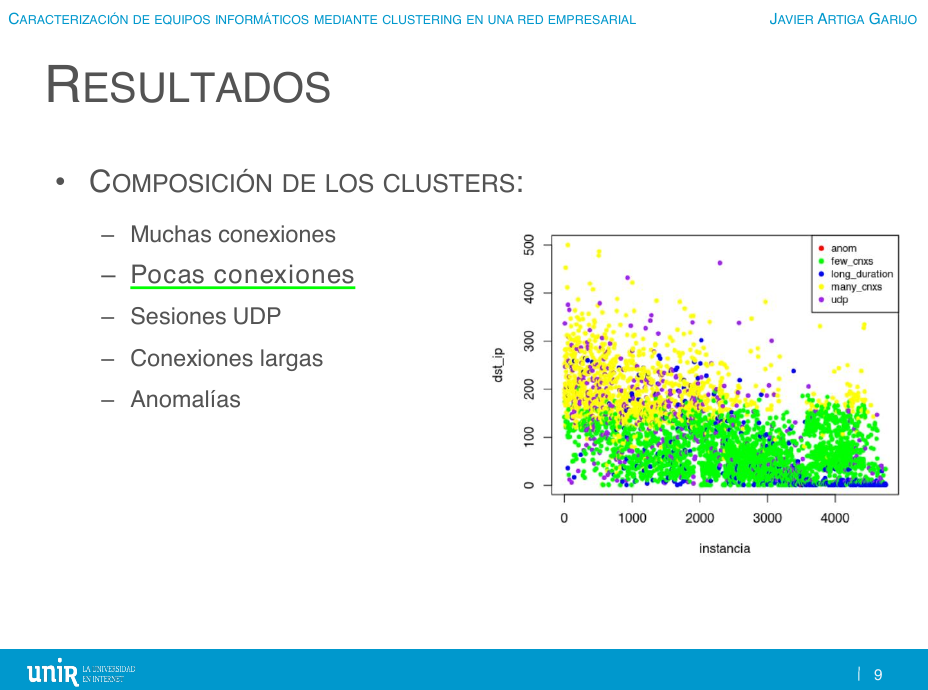
⠀
3. En los clasificados como "sesiones UDP" lo más destacado es que la característica "protocolo" es mayor que 1, lo que significa que se usa UDP de forma notable (a diferencia de las categorías de comportamiento normal anteriores, donde este valor es más cercano a 0). También suele haber más de 2 puertos destino y las sesiones son más largas de media que las de las categorías anteriores.

⠀
4. La cuarta categoría suele identificarse como "conexiones largas" porque la duración media de sesión está en el orden de decenas e incluso centenas de miles de segundos (esto es, mantienen sesiones que superan el día de duración).
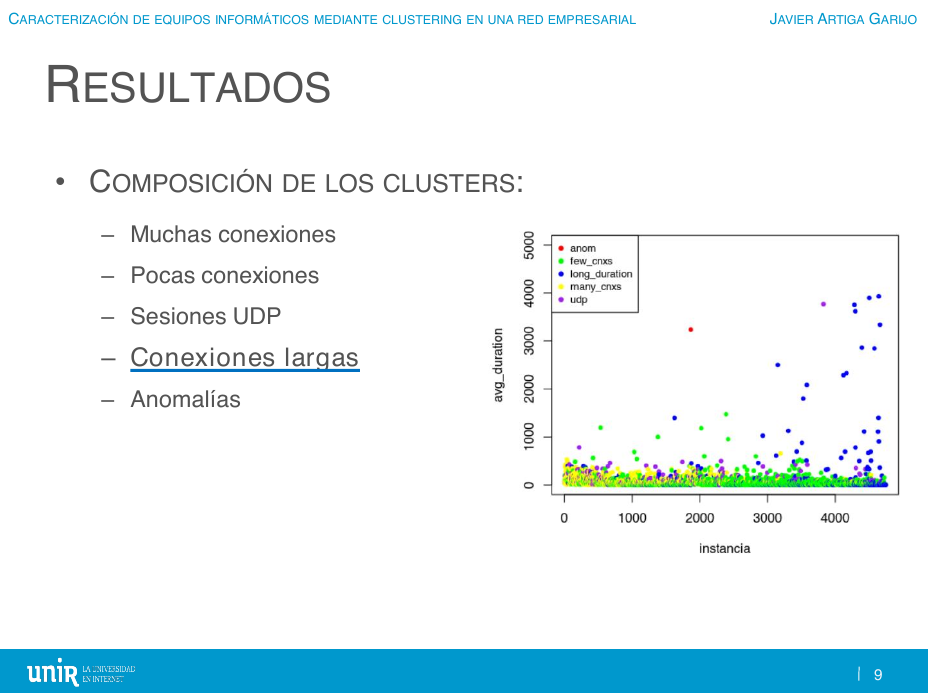
⠀
5. En el grupo denominado de las "anomalías", los valores son más extraños porque se compone de pocas instancias cuyas características son más extremas. Lo que más salta a la vista es que el número de eventos en estos casos es mucho mayor, y también el número de puertos origen (lo que indica que estos equipos mantienen una cantidad de sesiones mayor que el resto).
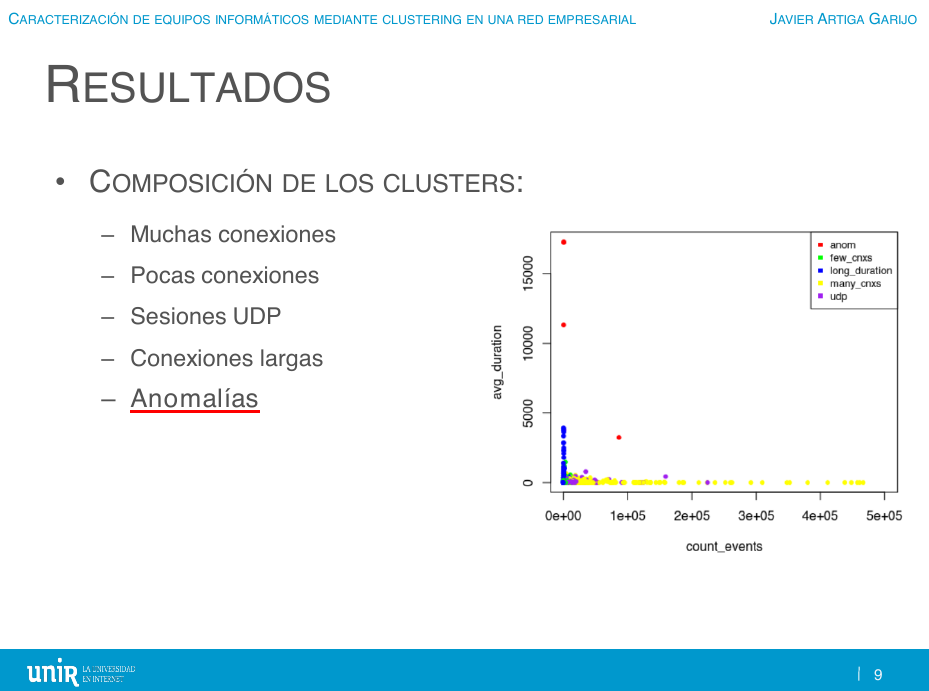
6. Conclusiones y líneas futuras
- Podemos clasificar las direcciones IP de una gran red empresarial en categorías relevantes según su comportamiento de red.
- Los equipos de la categoría "anomalías" ciertamente se identifican con comportamientos sospechosos (aunque no necesariamente malintencionados).
- Esta aportación puede tener una aplicación práctica inmediata.
Presentación de la defensa
